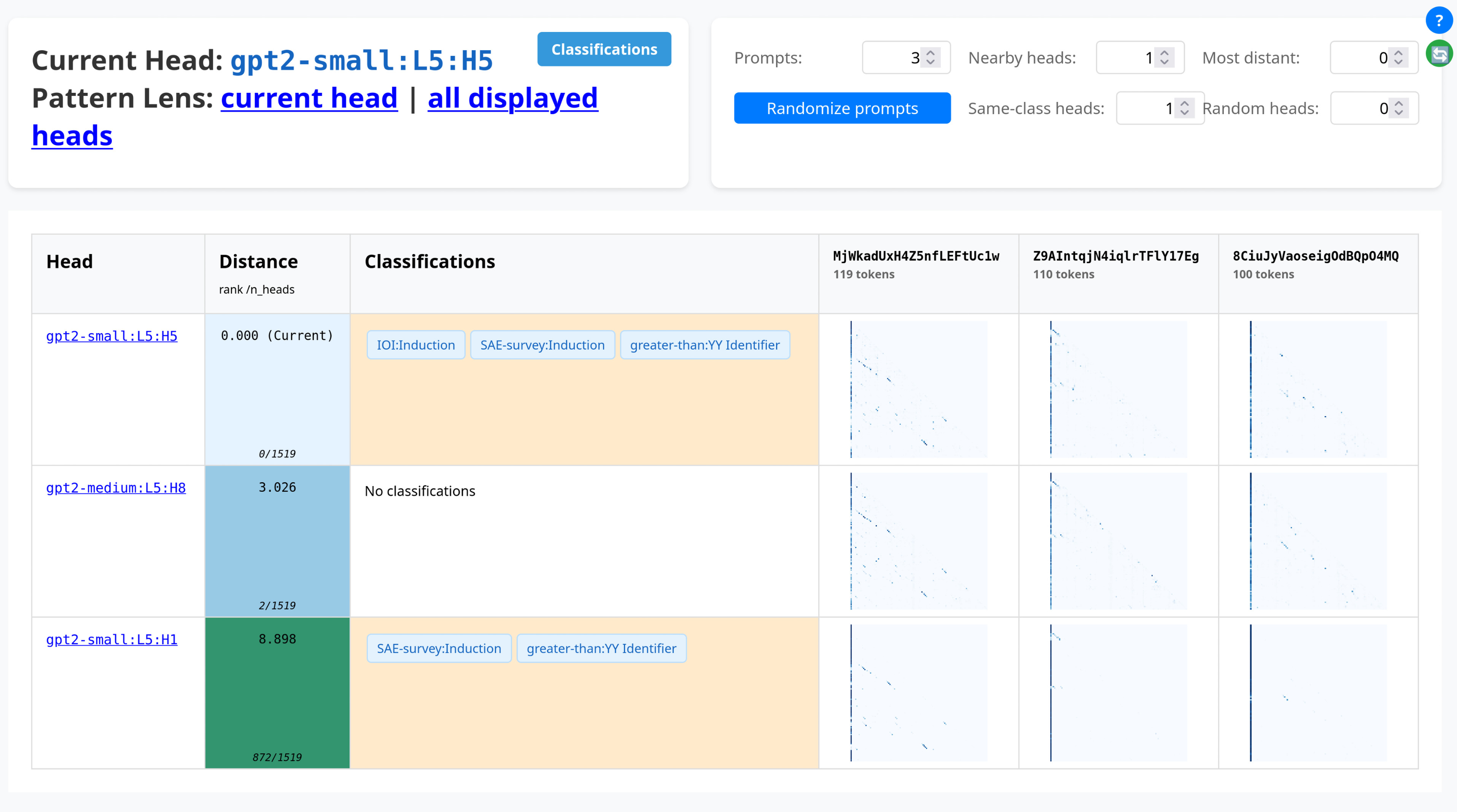
AttentionPedia
The central hub for exploring attention heads. Find similar heads, view patterns side-by-side, and navigate classifications.
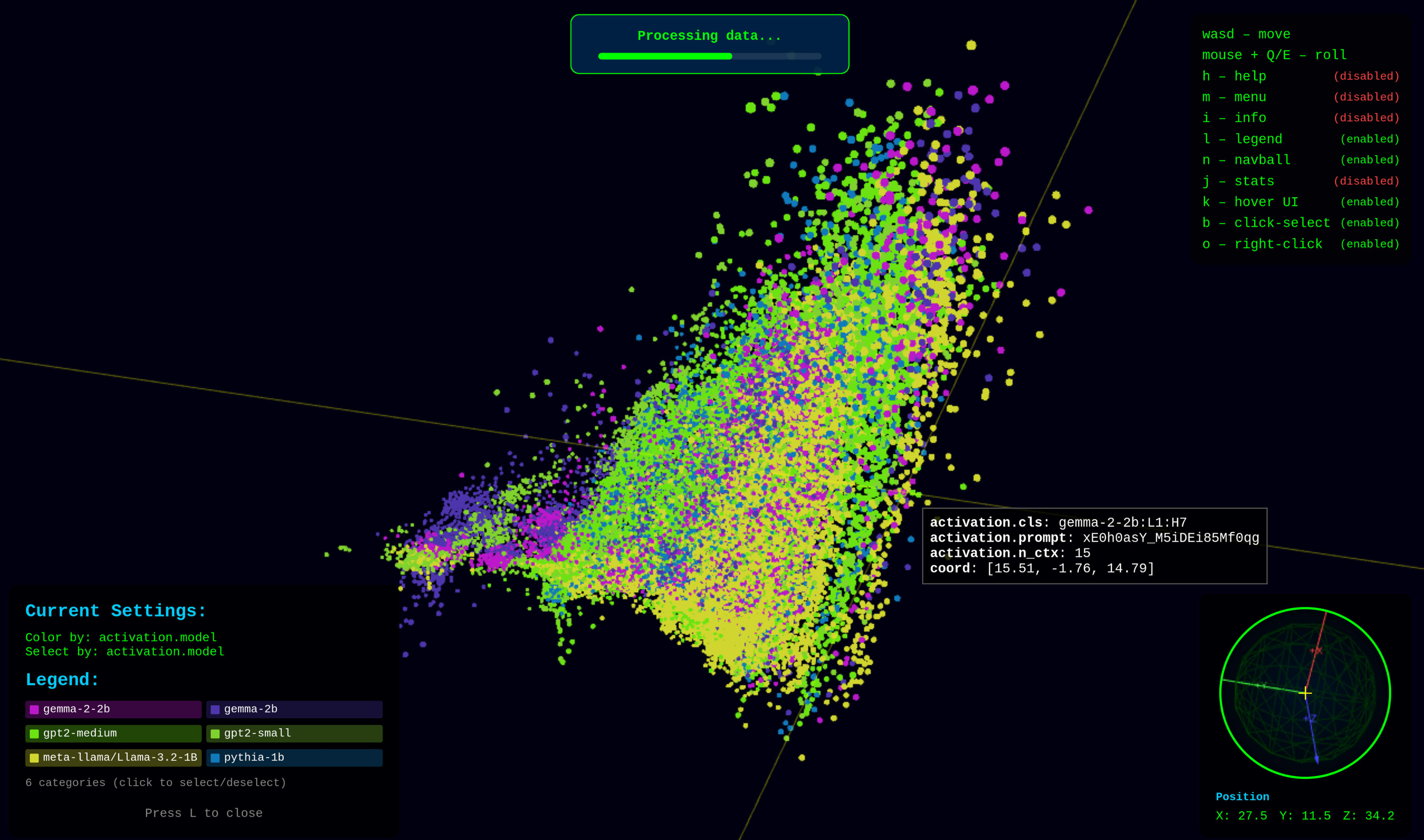
Pattern Embedding Visualization
Explore the 3D space of attention patterns. See how individual patterns relate to each other in the learned embedding.
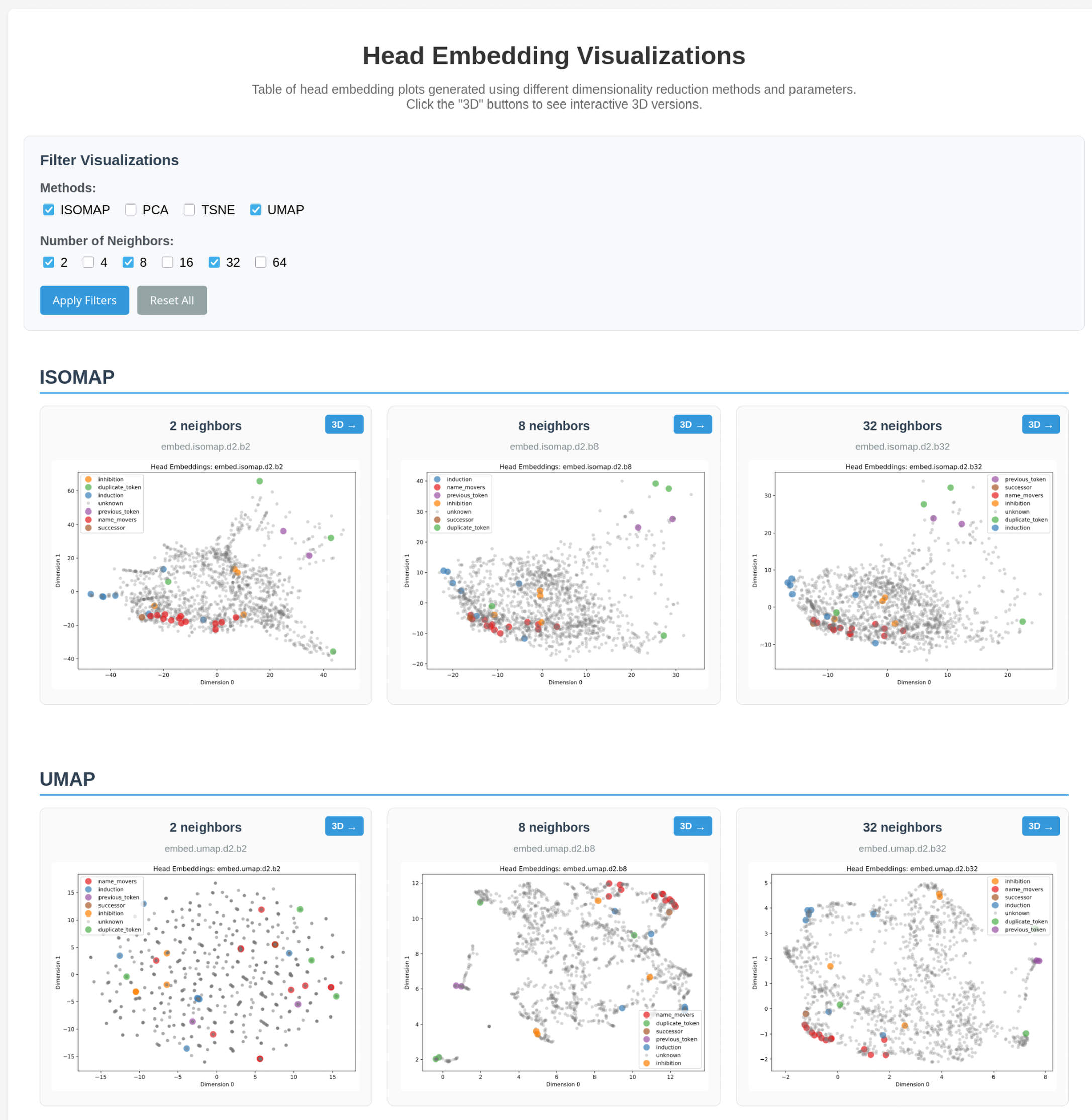
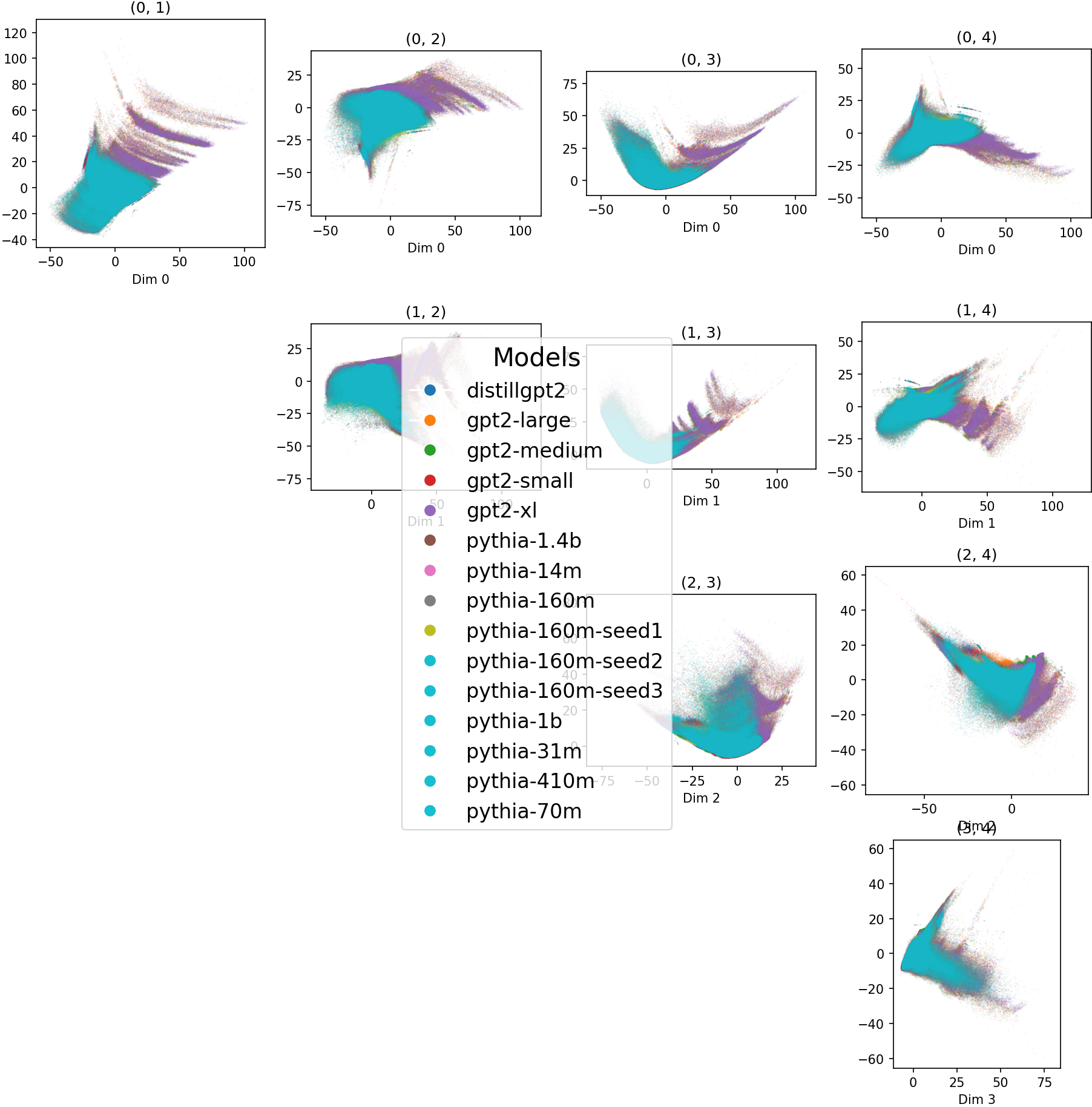
Head Embedding Table
Various embeddings of attention heads, with known classifications.
Clustering
Dendrogram and grid view of cluster assignments. Supports hierarchical, HDBSCAN, and Leiden clustering methods.
Cluster Trends
Cluster composition trends across models and layers. Analyze how clusters distribute across model families.
Ablation Interface
Explore ablation results for attention heads. Compare loss impact across heads, clusters, and model families.
{kind=link}