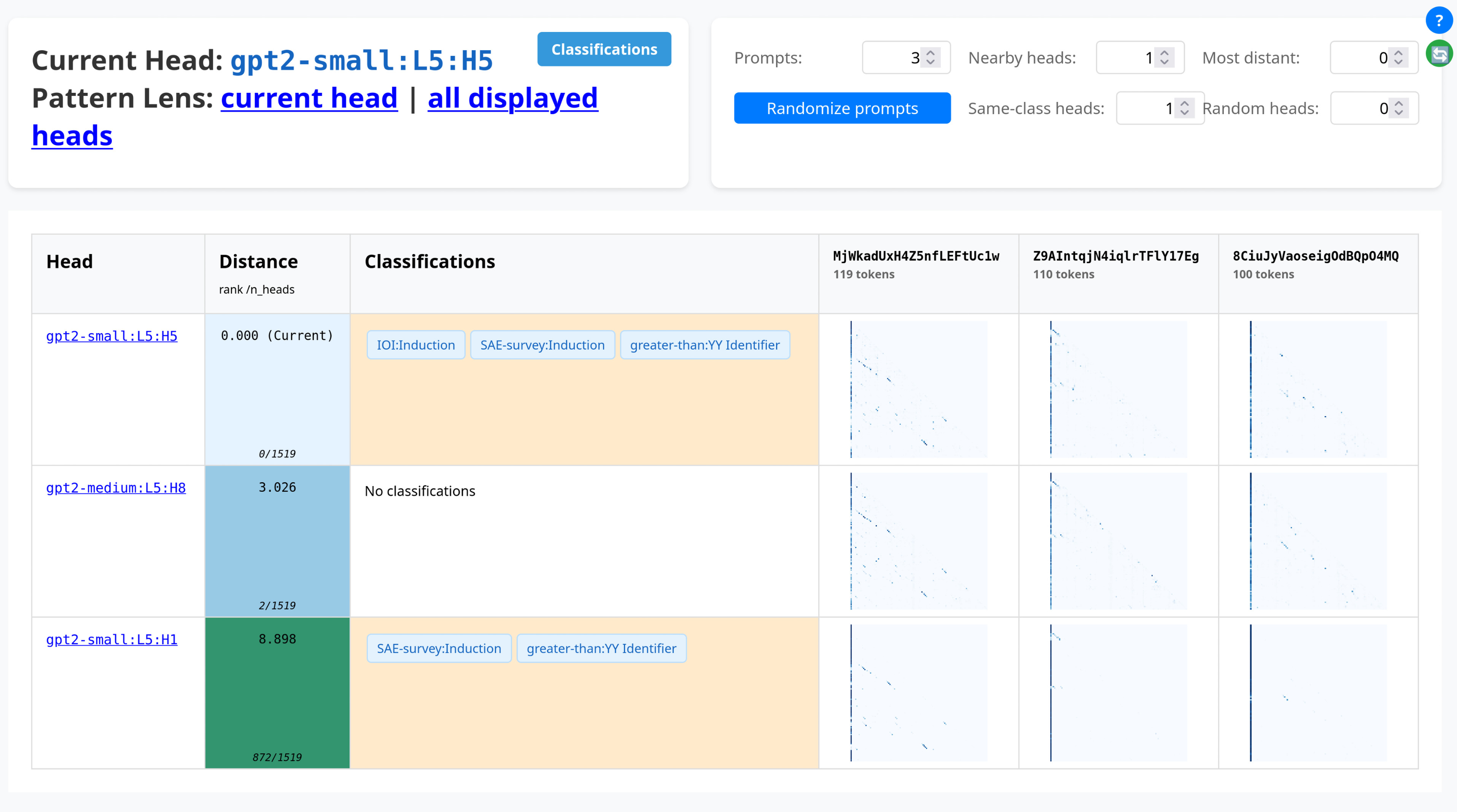
AttentionPedia
The central hub for exploring attention heads. Find similar heads, view patterns side-by-side, and navigate classifications.
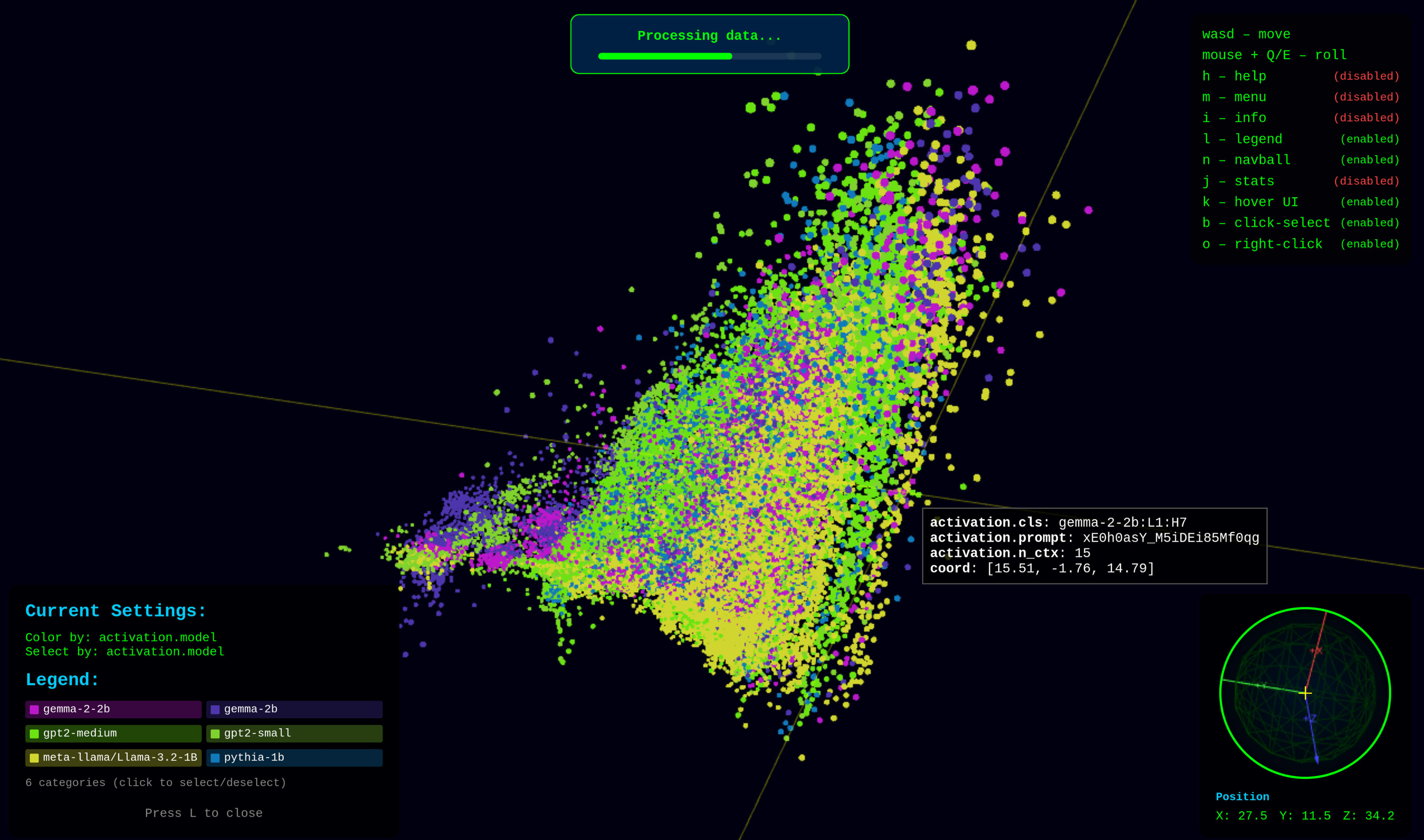
Pattern Embedding Visualization
Explore the 3D space of attention patterns. See how individual patterns relate to each other in the learned embedding. WASD to move, click+mouse to look around. left click to select, right click to open pattern, middle mouse button to bring up pattern view.
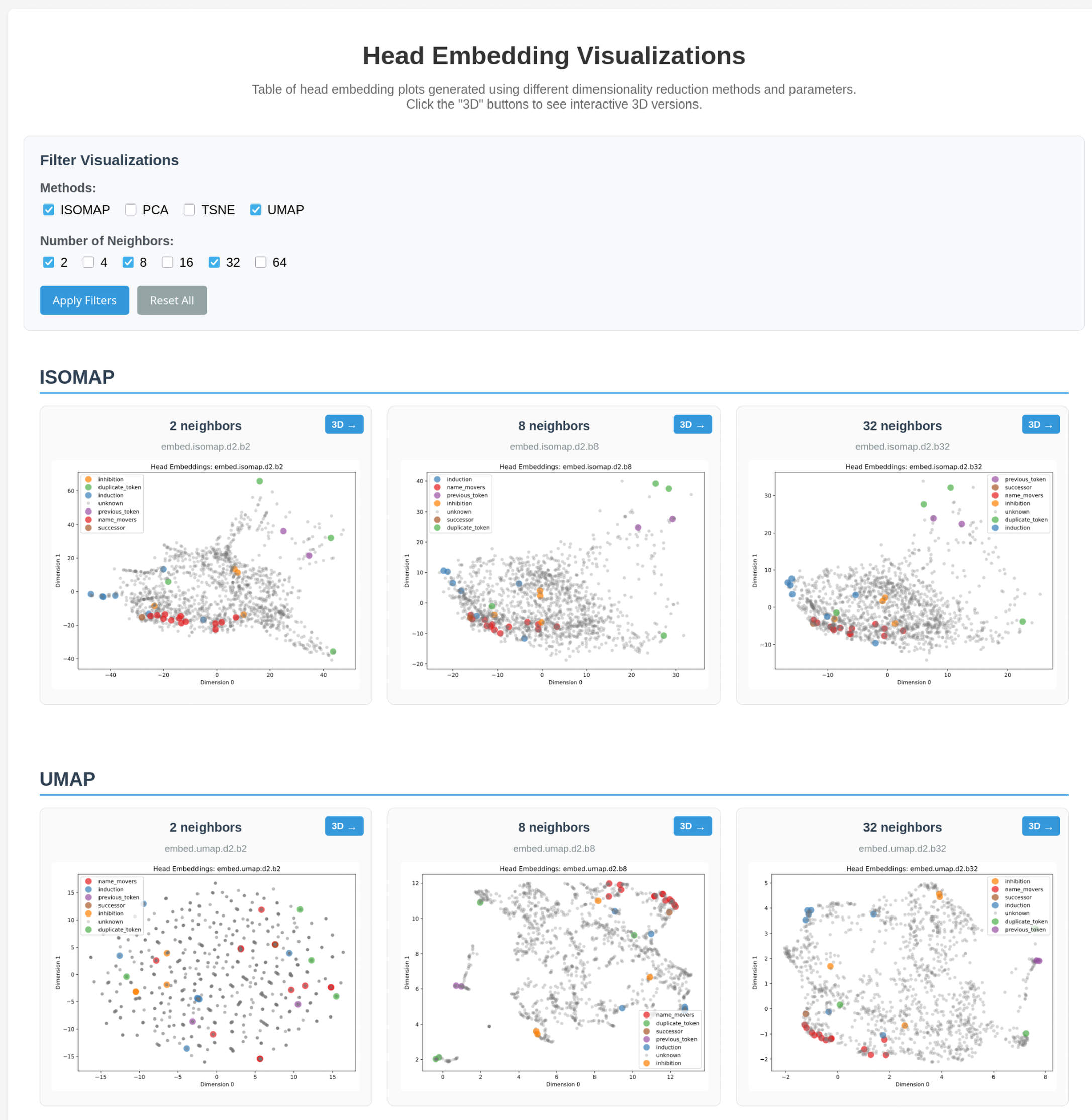
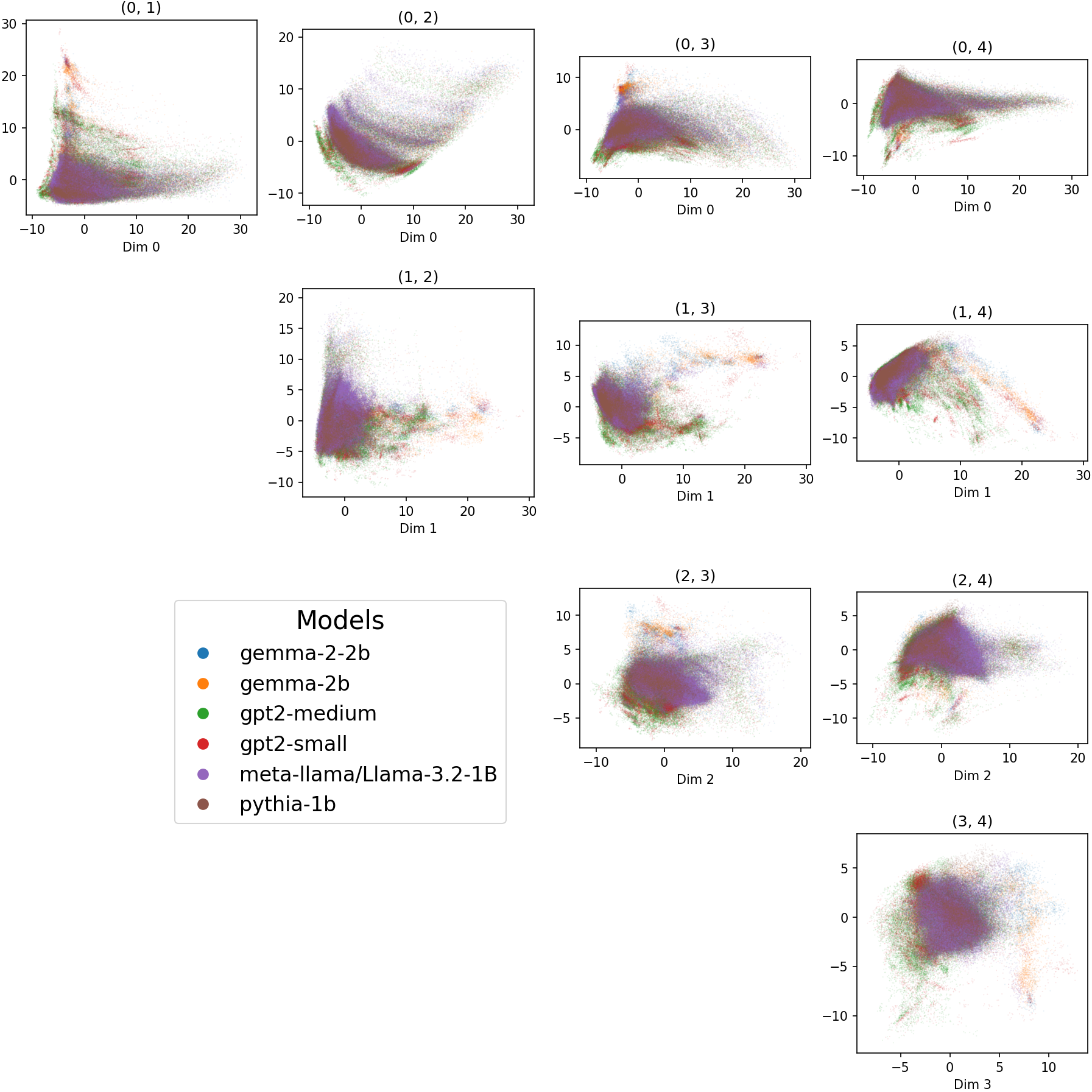
Head Embedding Table
Various embeddings of attention heads, with known classifications.
{kind=link}